Modifying SI4T to work with ALL new versions of Elasticsearch
Marko Milic
| Certified RWS Tridion architect and RWS Tridion MVP
|
Background Context:
Recently, we had a request from the client (Malvern Panalytical) to modify SI4T extension to be able to use their own Elasticsearch cloud instances with it.
For those rare of you, who aren't familiar, Malvern Panalytical (https://www.malvernpanalytical.com/) is a Spectris plc company. Their team is focused on the future regarding the technology they produce and the technologies they use, even striving to incorporate the best and latest trends in web development into their website. Learn more about Malvern Panalytical.
This brings me to the topic of implementing Elastic Cloud with Tridion (via SI4T).
When Elastic cloud was picked as a go-to search engine to power the website, the question that was asked and discussed was not simply "which search engine would power the website?" but "what should search experience look like in the next few years?" How would adopting Elasticsearch fit within the Tridion ecosystem and, even more importantly, in the company throughout? Can it be easily deployed, upgraded, monitored, or scaled up to meet current and future business needs?
The answer to these and a bunch of other excellent questions came in the form of cloud offerings as solutions, as opposed to the instances that come with Tridion installation, due to the following reasons:
Cloud offerings provide benefits like easier deployment and management of instances, tracing tools, etc., pretty much everything that a given cloud offering has in its portfolio.
It offers the newest instances of Elasticsearch from 7.17.4 onwards (up to 8.3.2 at the moment of writing this article), which is much newer than what Tridion has to offer (6.x).
The client plans to implement Elasticsearch broadly across the company, not just for Tridion, so it makes sense to go with a federated cloud offering.
In the end, they didn't want to settle with the single, on-prem instance of Elasticsearch that Tridion offers out-of-the-box, where version compatibility must be maintained as only what is supported by Tridion. They wanted to go beyond that. They wanted to integrate any version of Elasticsearch. They wanted to be able to upgrade the Elasticsearch instance in the cloud with a click (ok, maybe a few clicks) while publishing through Tridion continues functioning without even a hiccup.
And they got that!
Solution Overview:
Using SI4T, our main challenge to accomplish this was to update the SI4T deployer storage extension to work with the latest versions of Elasticsearch in the cloud (7.17.4 up to 8.3.2). During the process, we encountered a lot of constraints that guided us during the implementation process, and we will walk through each of them to share our lessons learned.
But we were successful! We didn't just survive; we thrived!
Let me explain how…
A bit about SI4T
As you are probably aware, SI4T or Search Integration for Tridion is an open-source project that helps you pull RWS Tridion CMS-managed content into your web app search index. It was primarily developed to allow you to push your content into Apache Solr. However, in the latest branches, it was customized to push content into Elasticsearch by Velmurugan Arjunan. You can read this blog of his, where he explains his enhancements in detail.
Templating
We did not change the templating output at all. The Template Building Blocks that generate SI4T output were not altered. The only change is in the storage extension. This was in alignment with one of our primary goals to minimize the customizations needed and leverage as much of SI4T as possible.
Updating the SI4T storage extension: the good, the bad, and the ugly!
The Good
The good news is that the only thing that SI4T does regarding Elasticsearch is that it drops prerendered documents to be indexed, or removed. Both actions are done using the bulk command, without additional code processing. So reimplementing that would be easy.
The Bad
The bad news was that SI4T was using the High Level Rest Client API to connect to the Elasticsearch instance. The High Level Rest Client was deprecated as of version 7.15.0 in favor of the Java API Client.
Even though the High Level Rest Client was still working with Elasticsearch 8.x, by enabling compatibility mode, it would still have to be rewritten at some time in the future. So sticking with it was not a valid long-term solution.
The Ugly
The SI4T storage extension is developed as a Java class library. It means that it is written in Java, and compiled against Java 11 (LTS) -- which is the requirement for the Tridion Deployer. However, Elasticsearch Java API Client libraries (.jar) are compiled and built against Java 18, which means that if you deploy them into a Tridion Deployer that runs under Java 11, it will fail.
Moreover, the Tridion Deployer itself has Elasticsearch libraries embedded. For example, Tridion Sites 9.6 comes with Elasticsearch 7.10.1 (which is no longer supported by Elasticsearch cloud). Injecting another set of Elasticsearch libraries will most definitely lead you to jar hell as it led me.
As frustrating as that was, I survived.
Here is how…
The elegant solution was waiting behind the obvious!
All the above constraints appeared to be incompatible. And those less brave would have given up claiming "it's not possible"… but if things were so easy then everyone could do it.
We spend a lot of time thinking long and hard about how to make these "irreconcilable differences" work. On how to make a marriage between the Tridion Deployer and Elasticsearch work in both the current versions and future versions; as well as how to ignore java versions and existing client libraries.
Finally, it hit me.
Forget the client libraries! Forget the reference to Elasticsearch Java API Client libraries altogether... Ultimately Elasticsearch is RESTful, and we can simply use the lower level HTTP POST API with JSON payloads to Elasticsearch within the SI4T code.
So that's what we did. We decided to completely scrap the idea of using Elasticsearch Java API Client libraries and just construct pure HTTP requests with JSON payload because, ultimately, that is how the client libraries interact with Elasticsearch anyway. Even the High Level Rest Client API was built on top of that!
Clearly, we would lose some level of abstraction that comes with supported client libraries. But, otherwise, we were blocked. There was no other way to proceed. The versioning of Elasticsearch APIs and instances were changing too often. This would require either constant upgrades, or we would be locked into a single version; forgoing all updates. It is almost the same situation that comes with Tridion out-of-the-box.
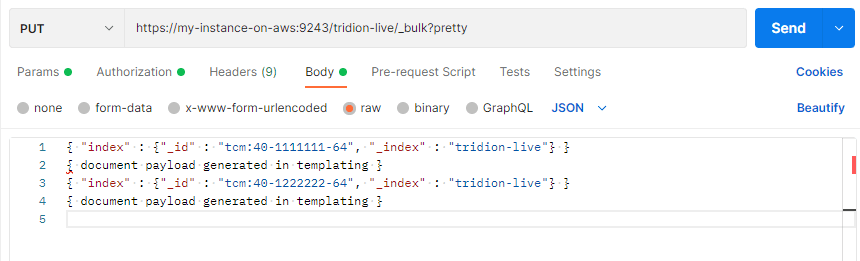
We can see how easy it is to execute the HTTP requests to Elasticsearch using Postman. For example, the image below illustrates the bulk request:
Performing a simple post to "/_bulk" endpoint
You can see that I am executing a PUT request to tridion-live index at the /_bulk endpoint with the ?pretty query string parameter. We are sending a JSON payload in the body of the request that states that we are sending two documents to be indexed along with the content of those documents. The content was generated by the SI4T Template Building Blocks during the Tridion Publishing process, and its structure has not changed. For more information on how to construct and use bulk requests, you can check the following documentation on the Elasticsearch website.
The bulk API allows us to execute multiple commands actions (index, create, delete and update), or combinations, in a single request. SI4T was originally only utilizing delete and index, where we enhanced the REST action to be a PUT request to now provide an update action. So, reconstructing these and generating JSON payload for them was straightforward.
The implementation for this can be observed in the ElasticSearchIndexDispatcher class. If you check addDocuments() and removeFromElasticSearch() methods in the same class, you will see that they use OkHttpClient to send post requests to Elasticsearch.
For example, the following piece of code demonstrates doing a bulk delete for documents:
What happens next is that Elasticsearch will return a JSON response payload with the status for each of the items. For example, this can be the sample payload for indexing the two above-mentioned documents in bulk:
A similar response payload can be obtained for either delete operations, or when there is an error.
You can see that there are no errors, as stated by "errors": false property. Additionally, for each document, you can see details and error-specific exceptions if existing.
I encapsulated the handling of all possible JSON response payloads so that any of them can be deserialized into the ElasticJsonResponse class. This makes working with various response types easy, and when anything unexpected is returned, the deserialization will throw an exception so that the publish transaction will be aborted.
Additional changes to make things even better!
Besides moving to HTTP-only requests, we made some additional changes that were required to make Elasticsearch work with the Tridion Deployer:
Remove index type/mapping type
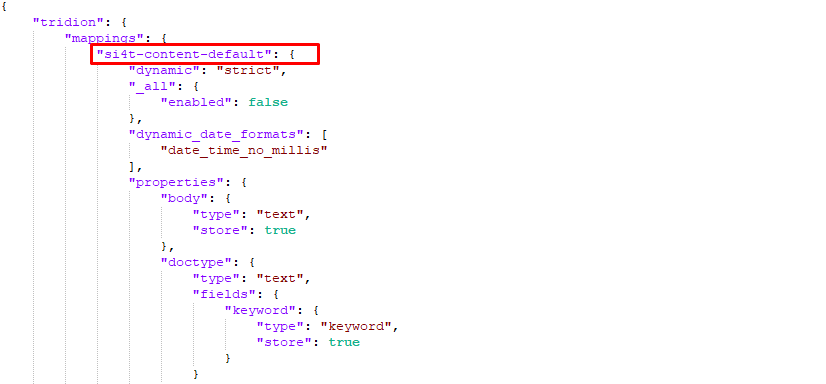
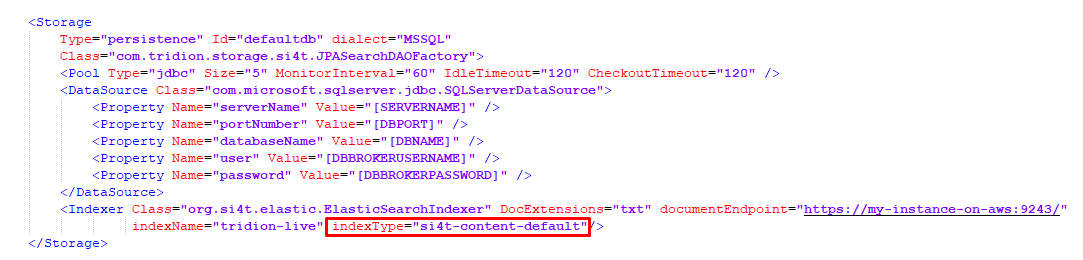
I removed mapping types from Elasticsearch mappings and from the deployer correlated indexType configuration; since they have been removed from Elasticsearch version 7.0.0, as noted in this documentation link.
"si4t-content-default" mapping type is removed from Elasticsearch mappings
"si4t-content-default indexType is removed from cd_storage_conf.xml"
This change is also done in the code; this property is removed and no longer supported or relevant.
Use Aliases
In Elasticsearch, Aliases are a secondary name for a group of data streams or indices. So, we added the alias "tridion-live" and configured it to include two indexes, "tridion-live-primary" and "tridion-live-secondary". Since only one of those indexes is active, the alias provides the ability to do operations on one while the other is active, and vice versa. We can also perform reindex operations from one onto the other with a simple alias switch. This provides resiliency while also simplifying the maintenance of the production cluster.
How to deploy?
The new SI4T Storage extension code is freely available on GitHub. It's a Java project (fork) of SI4T with maven configuration.
Assuming you are familiar with the Tridion Add-on Service ….the most complicated part here is that you will need to download the source project and compile/build it. Once you have successfully built the solution, the build folder will contain a si4t-elastic-1.0.jar along with all the dependencies like si4t-se-1.2.jar (for Tridion 9.1) and okHttp client.
You can copy these over to the zip file previously downloaded from Tridion. Or, if you are doing any modifications, all you need to do is just copy the newly built si4t-elastic-1.0.jar into si4t-deployer-extension-assembly-elastic-0.55.zip, which is a preconfigured add-on package. Don't be intimidated by the version. It only means that it took 54 wrong attempts to fix it!
After that, you are ready to deploy it to Tridion in Add-on UI.
Check out my blog here for additional details on how to build and deploy the SI4T deployer storage extension using the Tridion Add-on service.
Conclusion and Celebration
As a result, we are now able to update Elasticsearch instances seamlessly, with the click of a button and a simple sanity check to confirm that publishing is still working. The code has since been tested with four different versions of Elasticsearch, and all of them work exactly as expected – thanks to the client library agnostic REST API.
So not only have we accomplished the original goal, but we have also completely decoupled Elasticsearch from Tridion -- gaining the synergy between both platforms without interdependencies and constraints so that each can evolve!
We are utilizing the newest features that Elasticsearch has to offer while not thinking about if we must upgrade Tridion first. For me, it's a win-win situation.
If you have any questions or are interested in getting firsthand experience from us about search integration, feel free to contact us.
About Malvern Panalytical
Malvern Panalytical draws on the power of our analytical instruments and services to make the invisible visible and the impossible possible.
Through the chemical, physical and structural analysis of materials, their high-precision analytical systems and top-notch services support their customers in creating a better world. They help to improve everything from the energies that power and the materials they use to the medicines that cure us and the foods we enjoy.
They partner with many of the world's biggest companies, universities, and research organizations, that value Malvern Panalytical for the power of their solutions and also for the depth of their expertise, collaboration, and integrity.
Malvern Panalytical is committed to Net Zero in their own operations by 2030 and in their total value chain by 2040. This is woven into the fabric of their business, and they help their employees and customers think about their own part in creating a healthier, cleaner, and more productive world.
With over 2300 employees, Malvern Panalytical serves the world and is part of Spectris plc, the world-leading precision measurement group.